
https://jingyan.baidu.com/article/acf728fd48859ef8e510a32d.html
假设一个场景:公司内部有财务、OA、订单服务等各类相互独立的应用系统,员工张三对这些系统有操作权限,如果张三想要登录某个系统进行业务操作,那么他需要输入相应的账号与密码。想象一下,当公司内部有 100 个应用系统,张三是不是要输入 100 次用户名和密码进行登录,然后分别才能进行业务操作呢?显然这是很不好的体验,因此我们需要引入一个这样的机制:张三只要输入一次用户名和密码登录,成功登录后,他就可以访问财务系统、OA 系统、订单服务等系统。这就是单点登录。
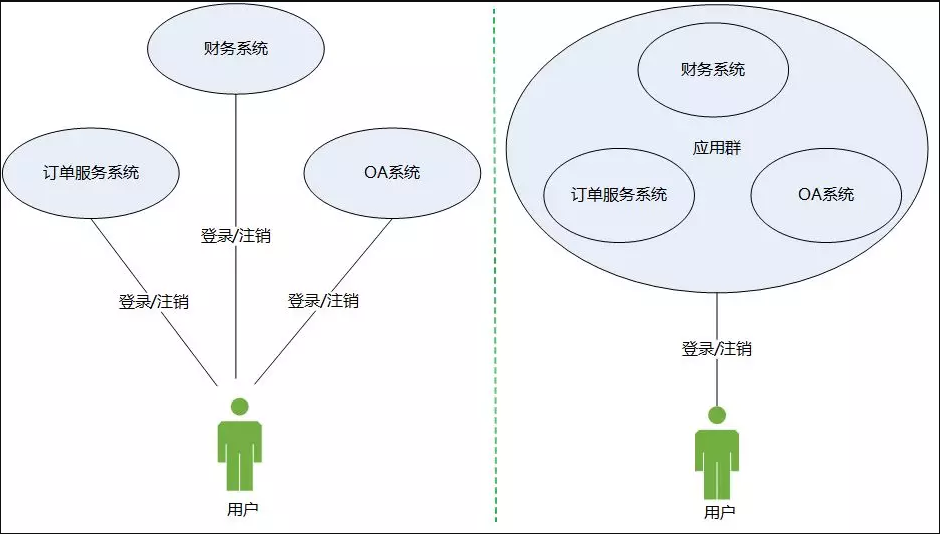
单点登录的英文全称是 Single Sign On,简称是 SSO。它的意思是说用户只需要登录一次,就可以在个人权限范围内,访问所有相互信任应用的功能模块,不管整个应用群的内部有多么复杂,对用户而言,都是一个统一的整体。用户访问 Web 系统的整个应用群与访问单个系统一样,登录和注销分别只要一次就够了。举个简单的例子,你登录了百度网页之后,点击跳转到百度贴吧,这时可以发现你已经自动登录了百度贴吧。
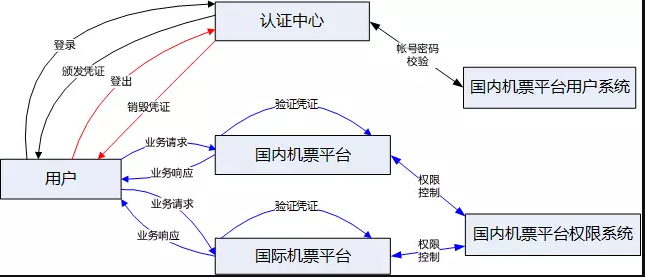
SSO 的技术实现要想做好并不容易,我们认为需求优先级应该先是单点登录和单点注销功能,然后是应用接入的门槛,最后是数据安全性,安全性对于 SSO 也非常重要。SSO 的核心是认证中心,但要实现用户一次登录,到处访问的效果,技术实现需要建立在用户系统、认证中心、权限系统、企业门户的基础上,各职责如下:
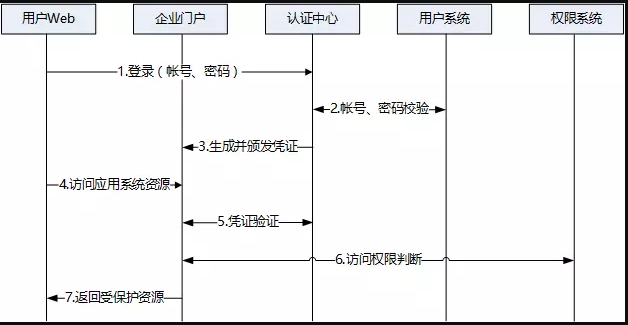

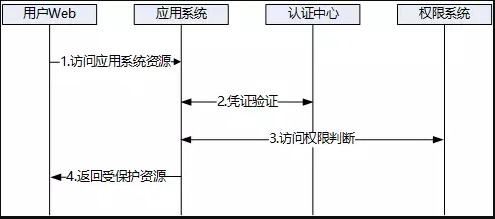
以上是用户的访问流程,如果用户没有有效的凭证,认证中心将强制用户进入登录流程。对于单点注销,用户如果注销了应用群内的其中一个应用,那么全局 token 也会被销毁,应用群内的所有应用将不能再被访问。
我们的应用接入与集成具体如下:
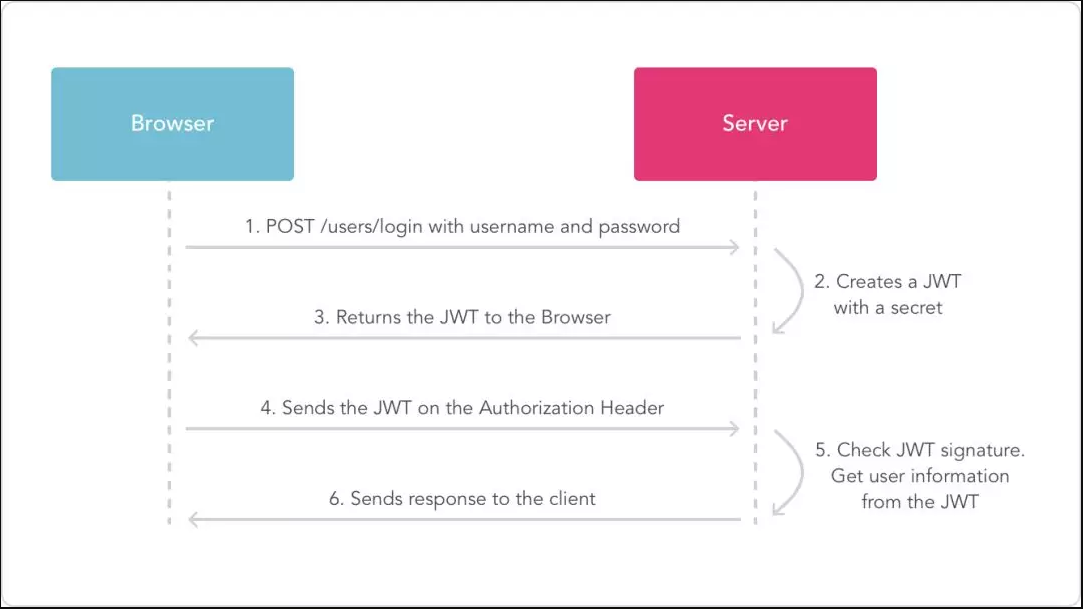
JSON Web Token (JWT) 是目前应用最为广泛的 token 格式,是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准(RFC 7519)。该 token 设计紧凑且安全,特别适用于分布式站点的单点登录、API 网关等场景。JWT 的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息。该 token 也可直接被用于认证,也可被加密。JWT 信息体由 3 部分构成:头 Header+ 载荷 Payload+ 签名 Signature,具体优点如下:
杨丽,拥有多年互联网应用系统研发经验,曾就职于古大集团,现任职中青易游的系统架构师,主要负责公司研发中心业务系统的架构设计以及新技术积累和培训。现阶段主要关注开源软件、软件架构、微服务以及大数据。
张辉清,10 多年的 IT 老兵,先后担任携程架构师、古大集团首席架构、中青易游 CTO 等职务,主导过两家公司的技术架构升级改造工作。现关注架构与工程效率,技术与业务的匹配与融合,技术价值与创新。
摘要: 网站数据统计分析工具是网站站长和运营人员经常使用的一种工具,比较常用的有谷歌分析、百度统计和腾讯分析等等。所有这些统计分析工具的第一步都是网站访问数据的收集。目前主流的数据收集方式基本都是基于javascript的。
网站数据统计分析工具是网站站长和运营人员经常使用的一种工具,比较常用的有谷歌分析、百度统计和腾讯分析等等。所有这些统计分析工具的第一步都是网站访问数据的收集。目前主流的数据收集方式基本都是基于javascript的。本文将简要分析这种数据收集的原理,并一步一步实际搭建一个实际的数据收集系统。
简单来说,网站统计分析工具需要收集到用户浏览目标网站的行为(如打开某网页、点击某按钮、将商品加入购物车等)及行为附加数据(如某下单行为产生的订单金额等)。早期的网站统计往往只收集一种用户行为:页面的打开。而后用户在页面中的行为均无法收集。这种收集策略能满足基本的流量分析、来源分析、内容分析及访客属性等常用分析视角,但是,随着ajax技术的广泛使用及电子商务网站对于电子商务目标的统计分析的需求越来越强烈,这种传统的收集策略已经显得力不能及。
后来,Google在其产品谷歌分析中创新性的引入了可定制的数据收集脚本,用户通过谷歌分析定义好的可扩展接口,只需编写少量的javascript代码就可以实现自定义事件和自定义指标的跟踪和分析。目前百度统计、搜狗分析等产品均照搬了谷歌分析的模式。
其实说起来两种数据收集模式的基本原理和流程是一致的,只是后一种通过javascript收集到了更多的信息。下面看一下现在各种网站统计工具的数据收集基本原理。
首先通过一幅图总体看一下数据收集的基本流程。

图1. 网站统计数据收集基本流程
首先,用户的行为会触发浏览器对被统计页面的一个http请求,这里姑且先认为行为就是打开网页。当网页被打开,页面中的埋点javascript片段会被执行,用过相关工具的朋友应该知道,一般网站统计工具都会要求用户在网页中加入一小段javascript代码,这个代码片段一般会动态创建一个script标签,并将src指向一个单独的js文件,此时这个单独的js文件(图1中绿色节点)会被浏览器请求到并执行,这个js往往就是真正的数据收集脚本。数据收集完成后,js会请求一个后端的数据收集脚本(图1中的backend),这个脚本一般是一个伪装成图片的动态脚本程序,可能由php、python或其它服务端语言编写,js会将收集到的数据通过http参数的方式传递给后端脚本,后端脚本解析参数并按固定格式记录到访问日志,同时可能会在http响应中给客户端种植一些用于追踪的cookie。
上面是一个数据收集的大概流程,下面以谷歌分析为例,对每一个阶段进行一个相对详细的分析。
若要使用谷歌分析(以下简称GA),需要在页面中插入一段它提供的javascript片段,这个片段往往被称为埋点代码。下面是我的博客中所放置的谷歌分析埋点代码截图:

图2. 谷歌分析埋点代码
其中_gaq是GA的的全局数组,用于放置各种配置,其中每一条配置的格式为:
Action指定配置动作,后面是相关的参数列表。GA给的默认埋点代码会给出两条预置配置,_setAccount用于设置网站标识ID,这个标识ID是在注册GA时分配的。_trackPageview告诉GA跟踪一次页面访问。更多配置请参考:https://developers.google.com/analytics/devguides/collection/gajs/。实际上,这个_gaq是被当做一个FIFO队列来用的,配置代码不必出现在埋点代码之前,具体请参考上述链接的说明。
就本文来说,_gaq的机制不是重点,重点是后面匿名函数的代码,这才是埋点代码真正要做的。这段代码的主要目的就是引入一个外部的js文件(ga.js),方式是通过document.createElement方法创建一个script并根据协议(http或https)将src指向对应的ga.js,最后将这个element插入页面的dom树上。
注意ga.async = true的意思是异步调用外部js文件,即不阻塞浏览器的解析,待外部js下载完成后异步执行。这个属性是HTML5新引入的。
数据收集脚本(ga.js)被请求后会被执行,这个脚本一般要做如下几件事:
1、通过浏览器内置javascript对象收集信息,如页面title(通过document.title)、referrer(上一跳url,通过document.referrer)、用户显示器分辨率(通过windows.screen)、cookie信息(通过document.cookie)等等一些信息。
2、解析_gaq收集配置信息。这里面可能会包括用户自定义的事件跟踪、业务数据(如电子商务网站的商品编号等)等。
3、将上面两步收集的数据按预定义格式解析并拼接。
4、请求一个后端脚本,将信息放在http request参数中携带给后端脚本。
这里唯一的问题是步骤4,javascript请求后端脚本常用的方法是ajax,但是ajax是不能跨域请求的。这里ga.js在被统计网站的域内执行,而后端脚本在另外的域(GA的后端统计脚本是http://www.google-analytics.com/__utm.gif),ajax行不通。一种通用的方法是js脚本创建一个Image对象,将Image对象的src属性指向后端脚本并携带参数,此时即实现了跨域请求后端。这也是后端脚本为什么通常伪装成gif文件的原因。通过http抓包可以看到ga.js对__utm.gif的请求:

图3. 后端脚本请求的http包
可以看到ga.js在请求__utm.gif时带了很多信息,例如utmsr=1280×1024是屏幕分辨率,utmac=UA-35712773-1是_gaq中解析出的我的GA标识ID等等。
值得注意的是,__utm.gif未必只会在埋点代码执行时被请求,如果用_trackEvent配置了事件跟踪,则在事件发生时也会请求这个脚本。
由于ga.js经过了压缩和混淆,可读性很差,我们就不分析了,具体后面实现阶段我会实现一个功能类似的脚本。
GA的__utm.gif是一个伪装成gif的脚本。这种后端脚本一般要完成以下几件事情:
1、解析http请求参数的到信息。
2、从服务器(WebServer)中获取一些客户端无法获取的信息,如访客ip等。
3、将信息按格式写入log。
5、生成一副1×1的空gif图片作为响应内容并将响应头的Content-type设为image/gif。
5、在响应头中通过Set-cookie设置一些需要的cookie信息。
之所以要设置cookie是因为如果要跟踪唯一访客,通常做法是如果在请求时发现客户端没有指定的跟踪cookie,则根据规则生成一个全局唯一的cookie并种植给用户,否则Set-cookie中放置获取到的跟踪cookie以保持同一用户cookie不变(见图4)。

图4. 通过cookie跟踪唯一用户的原理
这种做法虽然不是完美的(例如用户清掉cookie或更换浏览器会被认为是两个用户),但是是目前被广泛使用的手段。注意,如果没有跨站跟踪同一用户的需求,可以通过js将cookie种植在被统计站点的域下(GA是这么做的),如果要全网统一定位,则通过后端脚本种植在服务端域下(我们待会的实现会这么做)。
根据上述原理,我自己搭建了一个访问日志收集系统。总体来说,搭建这个系统要做如下的事:

图5. 访问数据收集系统工作分解
下面详述每一步的实现。我将这个系统叫做MyAnalytics。
为了简单起见,我不打算实现GA的完整数据收集模型,而是收集以下信息。
| 名称 | 途径 | 备注 |
| 访问时间 | web server | Nginx $msec |
| IP | web server | Nginx $remote_addr |
| 域名 | javascript | document.domain |
| URL | javascript | document.URL |
| 页面标题 | javascript | document.title |
| 分辨率 | javascript | window.screen.height & width |
| 颜色深度 | javascript | window.screen.colorDepth |
| Referrer | javascript | document.referrer |
| 浏览客户端 | web server | Nginx $http_user_agent |
| 客户端语言 | javascript | navigator.language |
| 访客标识 | cookie | |
| 网站标识 | javascript | 自定义对象 |
埋点代码我将借鉴GA的模式,但是目前不会将配置对象作为一个FIFO队列用。一个埋点代码的模板如下:
这里我启用了二级域名analytics.codinglabs.org,统计脚本的名称为ma.js。当然这里有一点小问题,因为我并没有https的服务器,所以如果一个https站点部署了代码会有问题,不过这里我们先忽略吧。
我写了一个不是很完善但能完成基本工作的统计脚本ma.js:
整个脚本放在匿名函数里,确保不会污染全局环境。功能在原理一节已经说明,不再赘述。其中1.gif是后端脚本。
日志采用每行一条记录的方式,采用不可见字符^A(ascii码0x01,Linux下可通过ctrl + v ctrl + a输入,下文均用“^A”表示不可见字符0x01),具体格式如下:
时间^AIP^A域名^AURL^A页面标题^AReferrer^A分辨率高^A分辨率宽^A颜色深度^A语言^A客户端信息^A用户标识^A网站标识
为了简单和效率考虑,我打算直接使用nginx的access_log做日志收集,不过有个问题就是nginx配置本身的逻辑表达能力有限,所以我选用了OpenResty做这个事情。OpenResty是一个基于Nginx扩展出的高性能应用开发平台,内部集成了诸多有用的模块,其中的核心是通过ngx_lua模块集成了Lua,从而在nginx配置文件中可以通过Lua来表述业务。关于这个平台我这里不做过多介绍,感兴趣的同学可以参考其官方网站http://openresty.org/,或者这里有其作者章亦春(agentzh)做的一个非常有爱的介绍OpenResty的slide:http://agentzh.org/misc/slides/ngx-openresty-ecosystem/,关于ngx_lua可以参考:https://github.com/chaoslawful/lua-nginx-module。
首先,需要在nginx的配置文件中定义日志格式:
注意这里以u_开头的是我们待会会自己定义的变量,其它的是nginx内置变量。
然后是核心的两个location:
要完全解释这段脚本的每一个细节有点超出本文的范围,而且用到了诸多第三方ngxin模块(全都包含在OpenResty中了),重点的地方我都用注释标出来了,可以不用完全理解每一行的意义,只要大约知道这个配置完成了我们在原理一节提到的后端逻辑就可以了。
真正的日志收集系统访问日志会非常多,时间一长文件变得很大,而且日志放在一个文件不便于管理。所以通常要按时间段将日志切分,例如每天或每小时切分一个日志。我这里为了效果明显,每一小时切分一个日志。我是通过crontab定时调用一个shell脚本实现的,shell脚本如下:
这个脚本将ma.log移动到指定文件夹并重命名为ma-{yyyymmddhh}.log,然后向nginx发送USR1信号令其重新打开日志文件。
然后再/etc/crontab里加入一行:
在每个小时的59分启动这个脚本进行日志轮转操作。
下面可以测试这个系统是否能正常运行了。我昨天就在我的博客中埋了相关的点,通过http抓包可以看到ma.js和1.gif已经被正确请求:

图6. http包分析ma.js和1.gif的请求
同时可以看一下1.gif的请求参数:

图7. 1.gif的请求参数
相关信息确实也放在了请求参数中。
然后我tail打开日志文件,然后刷新一下页面,因为没有设access log buffer, 我立即得到了一条新日志:
注意实际上原日志中的^A是不可见的,这里我用可见的^A替换为方便阅读,另外IP由于涉及隐私我替换为了0.0.0.0。
看一眼日志轮转目录,由于我之前已经埋了点,所以已经生成了很多轮转文件:

图8. 轮转日志
通过上面的分析和开发可以大致理解一个网站统计的日志收集系统是如何工作的。有了这些日志,就可以进行后续的分析了。本文只注重日志收集,所以不会写太多关于分析的东西。
注意,原始日志最好尽量多的保留信息而不要做过多过滤和处理。例如上面的MyAnalytics保留了毫秒级时间戳而不是格式化后的时间,时间的格式化是后面的系统做的事而不是日志收集系统的责任。后面的系统根据原始日志可以分析出很多东西,例如通过IP库可以定位访问者的地域、user agent中可以得到访问者的操作系统、浏览器等信息,再结合复杂的分析模型,就可以做流量、来源、访客、地域、路径等分析了。当然,一般不会直接对原始日志分析,而是会将其清洗格式化后转存到其它地方,如MySQL或HBase中再做分析。
分析部分的工作有很多开源的基础设施可以使用,例如实时分析可以使用Storm,而离线分析可以使用Hadoop。当然,在日志比较小的情况下,也可以通过shell命令做一些简单的分析,例如,下面三条命令可以分别得出我的博客在今天上午8点到9点的访问量(PV),访客数(UV)和独立IP数(IP):
其它好玩的东西朋友们可以慢慢挖掘。
GA的开发者文档:https://developers.google.com/analytics/devguides/collection/gajs/
一篇关于实现nginx收日志的文章:http://blog.linezing.com/2011/11/%E4%BD%BF%E7%94%A8nginx%E8%AE%B0%E6%97%A5%E5%BF%97
关于Nginx可以参考:http://wiki.nginx.org/Main
OpenResty的官方网站为:http://openresty.org
ngx_lua模块可参考:https://github.com/chaoslawful/lua-nginx-module
本文http抓包使用Chrome浏览器开发者工具,绘制思维导图使用Xmind,流程和结构图使用Tikz PGF
转自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html
https://blog.csdn.net/csdnnews/article/details/78248699
本文主要涵盖了 Python 编程的核心知识(暂不包括标准库及第三方库)。
按顺序依次展示了以下内容的一系列思维导图:基础知识,数据类型(数字,字符串,列表,元组,字典,集合),条件&循环,文件对象,错误&异常,函数,模块,面向对象编程。
14 张思维导图
基础知识


数据类型

序列

字符串

列表 & 元组

字典 & 集合

条件 & 循环

文件对象

错误 & 异常

函数


模块

面向对象编程

作者:ZY,来源:ZOE | 数林觅风 ,解释权归原作者所有,侵删。
物联网中的核心关键技术
核心关键技术主要有RFID技术、传感器技术、无线网络技术、人工智能技术、云计算技术等。
1、RFID技术
是物联网中“让物品开口说话”的关键技术,物联网中RFID标签上存着规范而具有互通性的信息,通过无线数据通信网络把他们自动采集到中央信息系统中实现物品的识别。

2、传感器技术
在物联网中传感器主要负责接收物品“讲话”的内容。传感器技术是从自然信源获取信息并对获取的信息进行处理、变换、识别的一门多学科交叉的现代科学与工程技术,它涉及传感器、信息处理和识别的规划设计、开发、制造、测试、应用及评价改进活动等内容。
3、无线网络技术
物联网中物品要与人无障碍地交流,必然离不开高速、可进行大批量数据传输的无线网络。无线网络既包括允许用户建立远距离无线连接的全球语音和数据网络,也包括近距离的蓝牙技术、红外技术和Zigbee技术。

4、人工智能技术
人工智能是研究是计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考和规划等)的技术。在物联网中人工智能技术主要将物品“讲话”的内容进行分析,从而实现计算机自动处理。
5、云计算技术
物联网的发展理离不开云计算技术的支持。物联网中的终端的计算和存储能力有限,云计算平台可以作为物联网的大脑,以实现对海量数据的存储和计算。

物联网中的技术难点
(1)数据安全问题
由于传感器数据采集频繁,基本可以说是随时在采集数据,数据安全必须重点考虑。
(2)终端问题
物联网中的终端除了具有自己的功能外还有传感器和网络接入功能,且不同的行业千差万别,如何满足终端产品的多样化需求,对研究者和运营商都是一个巨大挑战。
想得却不可得 你奈人生何
该舍的舍不得 只顾著跟往事瞎扯
等你发现时间是贼了 它早已偷光你的选择
原文:6 Simple Tips on How to Start Writing Clean Code
作者:Alex Devero
译者:Teixeira10
【译者注】作为一名开发者,编写一手干净的代码很重要,所以在本文中作者先列举出编写干净代码的一些好处,再提出6个技巧用于编写干净代码,供开发者进行参考学习。
以下为译文:
编写干净的代码并不是一件容易的事情,这需要尝试不同的技巧和实践。问题是,在这个问题上有太多的实践和技巧,因此开发人员很难进行选择,所以要把这个问题简化一下。在本文中,将首先讨论编写干净代码的一些好处,然后将讨论6个技巧或者实践,用于编写最常用的干净代码。
以下是目录内容:
编写干净代码的好处
1. 更容易开始和继续一个项目
2.有利于团队新员工培训
3.更容易遵循编码模式写干净代码的技巧
1.编写可读的代码
2.为变量、函数和方法使用有意义的名称
3.让每个函数或方法只执行一个任务
4.使用注释来解释代码
5.保持代码风格一致性
6.定期检查你的代码关于编写干净代码的一些想法
先来了解编写干净代码的一些好处。其中一个主要好处是,干净的代码可以减少花在阅读上的时间和理解代码的时间。凌乱的代码会减慢任何开发人员的速度,使开发者的工作变得更加困难。代码越混乱,开发人员就越需要花更多的时间去充分理解它,这样才能使用这些代码。而且,如果代码太乱,开发人员可能会决定停止阅读这些代码,并自己从头开始编写。
1.更容易开始和继续一个项目
先用一个简单的例子来说明这个问题。假设在很长一段时间后我们回到了之前的一个项目,也许在这段时间是一位客户联系我们去做了另一项工作。现在,想象一下,那时如果没有编写干净的代码,那么在第一眼看到代码之后,该是有多糟糕和混乱。而且,也可以知道从当初离开的地方开始编码有多困难。
因此,现在必须花更多的时间在项目上,因为我们需要理解之前编写的代码。这本来是可以避免的,如果从一开始就编写干净的代码,然而现在必须为此付出代价。而且,旧代码是如此混乱和糟糕,以至于我们可能决定从头开始。客户听到这些消息后可能不会高兴。
另一方面,干净的代码通常就没有这个问题。假设前面的例子是相反的情况,以前的代码是干净和优雅的,那么理解它需要多长时间?也许只需要读几分钟的代码就能理解所有的工作原理,而且我们可能已经开始编写一段时间了,所以在这种情况下花的精力将明显小于第一个案例,同时,客户也不会太在意。
这是编写干净代码的第一个好处,而且,这不仅适用于自己的项目,也适用于其他开发人员的工作。干净的代码可以更快地启动工作,任何人都不需要花费数小时来研究代码,相反,我们可以直接进入工作。
2.有利于团队新员工培训
编写干净代码的另一个好处与第一个好处是密切相关的,那就是可以让新员工更容易更快地使用代码。假设我们需要雇佣一个开发人员,那么她要花多长时间才能理解代码并学会使用它呢?当然这要视情况而定。如果我们的代码很乱,写得很差,她就需要花更多的时间来学习代码。另一方面,如果代码干净、易读、简单易懂,她将能够更快地开始她的工作。
有些人可能会说,这不是个问题,因为其他开发人员可以帮助她。当然这是正确的,但是帮助只应该花很短的时间,是两三次或者一两天,而并不应该是两三个星期。所以,决定雇佣另一个开发人员的目的,是来加速我们的工作,而不是减慢速度,也不是花费更多的时间来帮助她学会使用代码。
当我们努力写出干净的代码时,其他人就会向我们学习,也就更容易跟着写出干净的代码。当然,仍然需要留出一些时间来帮助每个新开发人员了解和理解代码。当然,我的意思是几天,而不是几周。此外,干净的代码将帮助团队带来更多的开发人员,并同时帮助他们理解代码。简单地说,代码越简洁就越容易解释,误解也就越少。
3.更容易遵循编码模式
有一件事需要记住,理解和学习如何使用代码是一回事。然而,这仅仅是个开始,同时还需要确保开发人员能够愿意遵循我们的编码模式。当然,使用干净的代码比混乱的代码更容易实现这个目标。这是很重要的,因为团队不仅想要编写干净的代码,而且还一直保持这种模式,这也是需要长期思考的。
另外,如果开发人员不遵循当前的编码模式该怎么办? 这个问题通常可以自行解决。假设有一群人在同一个代码基础上工作,其中一个人开始偏离标准样式。然后,团队的其他成员将推动这个开发人员遵循标准。她会接受建议,因为她不想离开这个团队。
还有一种情况,开发人员会说服团队的其他人采纳并遵循自己的编码模式。如果开发人员提出的编码模式更干净,并且能带来更好的结果,这当然是件好事。的确,编写和保持干净的代码并不意味着应该忽略任何改进它的机会,我认为应该始终对目前的做法保持可改进的态度,并努力寻找改进的机会。
因此,如果一个开发人员偏离了当前的模式,同时她的模式也更好,那么我们做出改变也许会更合适。所以在尝试其他模式之前,不应该忽视其他人的编码实践,同时我们应该继续寻找改进的余地。最后,第三种情况。开发人员决定既不采用我们的实践,也不说服我们采用她的实践。因为她将决定离开团队。
现在除了讨论编写干净代码的好处,也是时候学习一些技巧来帮助我们实现这个目标了。正如将在以下看到的,干净的代码包含并遵循着一些方法。这些方法使代码更干净、易读、更易于理解、更简单。当然没有必要实施所有的方法,实施并遵循一两项措施就足以带来积极的结果。
1.编写可读的代码
的确,所写的代码将会机器解释,然而这并不意味着应该忽视代码的可读性和可理解性,因为在将来总会有另一个人会使用我们写的代码。即使让别人无法访问我们的代码,但我们自己也可能在将来又重新拾起这些代码。出于这些原因,让代码便于阅读和理解是符合我们自己的利益的。那么如何实现呢?
最简单的方法是使用空格。在发布代码之前,可以缩减代码,但是没有必要让代码看起来很小型化。相反,可以使用缩进、换行和空行来使代码结构更具可读性。当决定采用这种方式时,代码的可读性和可理解性就会显著提高。然后,看着代码就可以更容易理解它了。来看两个简单的例子。
代码:
// Bad
const userData=[{userId: 1, userName: 'Anthony Johnson', memberSince: '08-01-2017', fluentIn: [ 'English', 'Greek', 'Russian']},{userId: 2, userName: 'Alice Stevens', memberSince: '02-11-2016', fluentIn: [ 'English', 'French', 'German']},{userId: 3, userName: 'Bradley Stark', memberSince: '29-08-2013', fluentIn: [ 'Czech', 'English', 'Polish']},{userId: 4, userName: 'Hirohiro Matumoto', memberSince: '08-05-2015', fluentIn: [ 'Chinese', 'English', 'German', 'Japanese']}];
// Better
const userData = [
{
userId: 1,
userName: 'Anthony Johnson',
memberSince: '08-01-2017',
fluentIn: [
'English',
'Greek',
'Russian'
]
}, {
userId: 2,
userName: 'Alice Stevens',
memberSince: '02-11-2016',
fluentIn: [
'English',
'French',
'German'
]
}, {
userId: 3,
userName: 'Bradley Stark',
memberSince: '29-08-2013',
fluentIn: [
'Czech',
'English',
'Polish'
]
}, {
userId: 4,
userName: 'Hirohiro Matumoto',
memberSince: '08-05-2015',
fluentIn: [
'Chinese',
'English',
'German',
'Japanese'
]
}
];代码:
// Bad
class CarouselLeftArrow extends Component{render(){return ( <a href="#" className="carousel__arrow carousel__arrow--left" onClick={this.props.onClick}> <span className="fa fa-2x fa-angle-left"/> </a> );}};
// Better
class CarouselLeftArrow extends Component {
render() {
return (
<a
href="#"
className="carousel__arrow carousel__arrow--left"
onClick={this.props.onClick}
>
<span className="fa fa-2x fa-angle-left" />
</a>
);
}
};2.为变量、函数和方法使用有意义的名称
来看一看第二个技巧,它将帮助我们编写可理解和干净的代码。这个技巧是关于变量、函数和方法的有意义的名称。“有意义的”是什么意思?有意义的名字是描述性足够多的名字,而不仅仅是编写者自己才能够理解的变量、函数或方法。换句话说,名称本身应该根据变量、函数或方法的内容和使用方式来定义。
代码:
// Bad
const fnm = ‘Tom’;
const lnm = ‘Hanks’
const x = 31;
const l = lstnm.length;
const boo = false;
const curr = true;
const sfn = ‘Remember the name’;
const dbl = [‘1984’, ‘1987’, ‘1989’, ‘1991’].map((i) => {
return i * 2;
});
// Better
const firstName = ‘Tom’;
const lastName = ‘Hanks’
const age = 31;
const lastNameLength = lastName.length;
const isComplete = false;
const isCurrentlyActive = true;
const songFileName = ‘Remember the name’;
const yearsDoubled = [‘1984’, ‘1987’, ‘1989’, ‘1991’].map((year) => {
return year * 2;
});然而需要注意的是,使用描述性名称并不意味着可以随意使用任意多个字符。一个好的经验则是将名字限制在3或4个单词。如果需要使用超过4个单词,说明这个函数或方法需要同时执行很多的任务,所以应该简化代码,只使用必要的字符。
3.让一个函数或方法只执行一个任务
当开始编写代码时,使用的函数和方法看起来就像一把瑞士军刀,几乎可以处理任何事情,但是很难找到一个好的命名。另外,除了编写者,几乎没有人知道函数是用来做什么的以及该如何使用它。有时我就会遇到这些问题,我在这方面做的很不好。
然后,有人提出了一个很好的建议:让每个函数或方法只执行一个任务。这个简单的建议改变了一切,帮助我写出了干净的代码,至少比以前更干净了。从那以后,其他人终于能够理解我的代码了,或者说,他们不需要像以前一样花很多时间去读懂代码了,功能和方法也变得更好理解。在相同的输入下,总是能产生相同的输出,而且,命名也变得容易得多。
如果你很难找到函数和方法的描述性名称,或者需要编写冗长的指令以便其他人可以使用,那请考虑这个建议,让每个函数或方法只执行一个任务。如果你的功能和方法看起来像瑞士军刀一样无所不能,那请你执行这个方法,相信我,这种多才多艺不是一种优势。这是一个相当不利的情况,可能会产生事与愿违的结果。
附注:这种让每一个函数或方法只执行一项任务的做法被称为保持纯函数。这种编码实践来自于函数式编程的概念。如果你想了解更多,我推荐阅读《So You Want to be a Functional Programmer series[4]》。
代码:
// Examples of pure functions
function subtract(x, y) {
return x - y;
}
function multiply(x, y) {
return x * y;
}
// Double numbers in an array
function doubleArray(array) {
return array.map(number => number * 2)
}4.更容易遵循编码模式
不管多么努力地为变量、函数和方法想出有意义的名字,代码仍然不可能完全清晰易懂,还有一些思路需要进行解释。问题可能不是代码很难理解或使用,相反,其他人可能不理解为什么要实现这个函数或方法,或者为什么要以特定的方式创建它。意思是,创建函数或方法的意图还不清楚。
有时可能不得不采用非传统的方法来解决问题,因为没有足够的时间来想出更好的解决方案,这也很难用代码来解释。所以,通过代码注释可以帮助解决这个问题,也可以帮助我们向其他人解释为什么写了这个方法,为什么要用这种特定的方式来写,那么其他人就不必猜测这些方法或函数的用途了。
更重要的是,当我们使用注来解释代码后,其他人可能会找到一个更好的方法来解决这个问题并改进代码。这是有可能的,因为他们知道问题是什么,以及期望的结果是什么。如果不知道这些信息,其他人就很难创建更好的解决方案,或者他们可能不会去尝试,因为他们认为没有必要去修改创建者自己的想法。
因此,每当自己决定使用一些快速修复或非传统的方法时,要用注释来解释为什么这么做。最好是用一两行注释来解释,而不用别人来猜测。
也就是说,我们应该只在必要的时候使用注释,而不是解释糟糕的代码。编写无穷无尽的注释将无助于将糟糕的代码转换成干净的代码。如果代码不好,应该通过改进代码来解决这个问题,而不是添加一些如何使用它的说明。编写干净的代码更重要。
5.保持代码风格一致性
当我们有自己喜欢的特定编码方式或风格时,就会在任何地方一直使用它。但在不同的项目中使用不同的编码风格不是一个好主意,而且也不可能很自然地回到以前的代码,所以仍然需要一些时间来理解在项目中使用的编码风格。
最好的方法是选择一套编码方式,然后在所有的项目中坚持使用。这样的话,回到之前的旧代码会变得更容易。当然,尝试新的编码方式是一件好事,它可以帮助我们找到更好的方法来开展工作。但是最好是在不同的实验项目或练习上尝试不同的编码风格,而不是在主要项目上进行。
另外,当我们决定做一些试验的时候,就应该尝试多次练习,应该花时间彻底地做好。只有真正确信喜欢这种做法,并且对它感到满意时,才应该去实施它。而且决定这样做的时候,最好应用在所有的项目中。是的,这需要时间,这也会促使我们正确地思考。
6.检查你的代码
这是最后一个技巧。不仅仅是编写干净的代码,还要完成最后的工作,那就是需要维护干净代码。我们应该定期检查代码,并试着改进它。否则,如果不审查和更新我们的旧代码,它很快就会过时,就像我们的设备一样。如果想让代码保持最佳状态,就需要定期更新它们。
对于每天使用的代码,情况也是如此。代码会变得更加复杂和混乱,所有应该避免这种情况发生,并保持代码干净。实现这一点的唯一方法是定期检查我们的代码。换句话说,我们需要保持它。对于那些未来不再关心的项目来说,这可能是不必要的,但对其他的来说,维护代码是工作的一部分。
今天讨论的这六种做法,可能不是影响最大的,也可能不是最重要的,但这些是经验丰富的开发人员最常提到的,这也就是我选择它们的原因。我希望这些实践或技巧能够帮助你开始编写干净的代码。现在,就像所有的事情一样,最重要的是开始。所以,至少选一个技巧,然后试一试。

对于如何进行代码重构,一直有着很多种说法。很多人都认为应该将重构代码放在backlog里。但是其实,这并不是一个理想的方法。

在项目刚刚开始的时候,你的代码很干净。

即使有的时候需要小小的绕一下路,但是这个时候我们可以轻松、平稳的添加功能。这个阶段一般都不会出现问题,而且由于我们比较着急,所以即使出现了一些小问题,我们也不会注意到。

然而,随着项目做的时间变长,这些小的问题就会累计起来。这就是人们所说的“技术债务”。其本质,就是并不算特别好的代码,但是这个时候其问题还没有完全显现出来。

但是,随着我们一直添加新功能,这些问题就会逐渐显现出来,我们不得不小心翼翼的绕开他们。

不可避免的,我们的开发速度会被拖慢。但是为了追求速度,我们开始变得越来越不小心,不久之后,问题也会越来越多。

这些问题会像积木一样累计起来,层层叠叠,让我们的开发速度变得更慢。虽然我们终于意识到了问题的存在,但是没有时间彻底解决它。我们只能继续小心翼翼的绕开它们。

很快,我们会发现半数以上的代码都与那些小问题有交集,它们无时无刻不在影响我们的开发速度。直到有一天,你发现自己没法继续绕开它们。

不得不做点事情了。我们必须要进行复杂的代码重构,让我们重新获得干净的代码。你不得不向上级申请时间进行代码重构。其实这种工作方式并不好,我们花时间去填自己以前挖的坑。而且有的时候,公司并没有让你去重构代码的时间。

即使公司给你时间了,你也很难很好的对代码进行重构。要知道,重构代码所需的时间,往往要远高于你的预期。如果这些纷乱的代码是你用了10周写出来的,那么你很难再用10周的时间对它们进行重构。
由此可见,这种代码重构的方式并不好。那么我们应该怎么做呢?

很简单,那就是每遇到一个问题,就马上解决它,而不是选择绕过它。完善当前正在使用的代码,那些还没有遇到的问题,就先不要理它。在当前前进的道路上,清除所有障碍,以后你肯定还会再一次走这条路,下次来到这里的时候你会发现路上不再有障碍。软件开发就是这样。
或许解决这个问题需要你多花一点时间。但是从长远来看,它会帮你节省下更多的时间。

在添加新功能的时候,我们就先清理这个功能所需要的代码。花一点时间,用滴水穿石的方法逐渐清理代码,随着时间的推移,我们的代码就会越来越干净,开发速度也会越来越快。

一段时间之后,你会发现之前所有的技术债务都不见了,所有的坑都被填平了。这种循序渐进的代码重构的好处开始显现,编程的速度明显加快
这才是代码重构的正确打开方式!
随着大数据在人们工作及日常生活中的应用,大数据可视化也改变着人类的对信息的阅读和理解方式。从百度迁徙到谷歌流感趋势,再到阿里云推出县域经济可视化产品,大数据技术和大数据可视化都是幕后的英雄。今天,我们将连载由Teradata独家提供的来自全球28个大数据可视化应用案例。文章中不仅有极具艺术美感的可视化炫图,更有作者为大家解析可视化是如何制作的。
本系列4篇文章为36大数据独家专稿,任何不表明来源36大数据和Teradata以及本文链接http://www.36dsj.com/archives/41214的转载均为侵权。公众号也是如此。
一、航线星云
作者:Karthik Guruswamy

关于洞察
截止到2012年1月,开源网站OPENFLIGHTS.ORG上记载了大约6万条直飞航班信息,这些航班穿梭在3000多个机场间,覆盖了500多条航线。
通过高级分析技术,我们可以看到世界上各家不同的航空公司看起来就像是一个美丽的星云(国际星云的组成部分)。同种颜色的圆点和粗线提供了见解,它们代表提供相同航线的航空公司,显示出它们之间的竞争以及在不同区域间的潜在合作。
这张基于数据可视化的Sigma图表显示了服务城市相似的不同航空公司。图中的圆点或圆圈代表航空公司,连线的粗细和远近则反映两个航空公司之间的相似性;连线越粗或越短则代表两家航司服务的城市越相似。图表中有几组航空公司,直观地表现了它们所服务的地理区域。
这张图表中的关键洞察当然地是航空公司之间的相似性甚至是重叠,它们是中国的南航和东航、阿联酋航空和卡塔尔航空、英航和汉莎航空、美航和达美航空;我们可以从中看出这些公司之间的竞争关系。瑞安航空则通过服务与汉莎航空和英航存在潜在协力的城市占据了一个利基市场;比起意大利或汉莎等其他的欧洲航司,法国航空则与美国联航等美国航空公司更为相似,这也许可以解释为联合品牌效应。本质上说,这是一张多维的韦恩图,用一种简明扼要的方式揭示了不同主体间的复杂关系。
总的来说,这张图表揭示了不同航司之间的相似性和竞争情况,有利于发掘潜在的合作关系、增加市场份额和市场覆盖面。这项技术可以通过不同参与者之间的相同变量,用于分析任何生态系统。
分析技术
这张可视化图表通过Aster App中心生成,运用到了关联挖掘的分析技术,研究上下文中各条目的共现关系。其中关联挖掘的算法是协同过滤,它作用于航线和城市数据,并将数据当做零售篮子数据。也就是说,篮子代表城市,而航空公司则是条目。两个航司之间的相似性由相似性得分确定,计分的原则是比较各个航司独有的航线以及同时运营的航线。之后再将这些成对的相似性得分当做连线的权重,再把各个航司当做节点,共同输入可视化仪器当中,运用具有模块上色技术的force-atlas算法,最终生成出这张美丽的图表。
二、Calling Circles
作者:Christopher Hillman

关于洞察
我们无论何时何地都在使用手机并且产生出非常大量的资料,这些资料代表了我们每天的行为及活动。我们与其他人的每通电话及简讯都对应到我们的社会关系、商业活动以及更广泛的社群互动并且形成了许多复杂互相联结的通话圈。
这个资料视觉化图表是从行动电话使用者的通话模式资料所制作的。每个点都代表一个使用者拨出的手机号码,愈大的点就代表这个号码被拨打愈多次。每条两点之间的线都代表着从一个号码拨打到另一个号码。
每个行动电话使用者都会有一种独特的通话模式,这种模式可以用来发展适合的话费方案并且可以用来定义或预测他/她的行为。举例来说,当一个使用者正要从现在的行动电话服务商转换到另一个服务商时,我们可以从网内及网外发现两个类似的通话模式。
这张特别的图表是在前期由一连串的分析产生用来过滤第一层的通话模式。这里使用到的资料只从在几秒钟的时间取得。从图表的左上角可以看到许多大回圈,这些回圈表示短时间内这些号码被拨打了许多次。可以推测这些号码有可能是机器,像是自动答录机、互动式语音应答(IVR) 系统、安全系统或警报。人类不可能在短时间拨出这么多电话。这些电话会先放置在一个分开的群组,后续的分析就可以集中在个人使用者的通话模式上。
分析技术
我们利用图表来达成资料视觉化,虽然在调整版面格式的参数与传统展示图表不同。有一个常见的问题就是这些互连的图表通常在短时间就会变成非常巨大且因为庞大的互动次数导致几乎不可能被视觉化。从一个高度连结的图表里选出一段范例是一个困难的问题,因为我们需要决定忽略哪些连结。在这个例子里,我们取用来自非常短的时间的资料来达到一个可以呈现的资料范围。
资料格式就相对简单,拨话号码、收话号码、拨话时间、通话时间。我们先利用机器学习(machine-learning) 来对资料作分群然后再利用Aster Lens 来展示图表。
Calling Circles作者介绍

Christopher Hillman
Christopher Hillman 跟他的妻子及两个小孩住在英国伦敦,在Teradata 的进阶分析团队(Advanced Analytics team) 担任首席资料科学家在全世界旅行工作。
他钟情于分析工作且有二十年的经验于商业智慧(business intelligence) 及进阶的分析产业。在Teradata 之前,Chris在Retail 和CPGN vertical作为一位解决方案架构师(solution architect)、首席顾问及技术总监。 Chris 现在与Teradata Aster 专家一同工作且参与大数据的分析专案,他帮助客户洞察资料中的价值并且了解MapReduce 或SQL 作为合适的技术。
在Teradata 工作的期间,Christopher 也同时攻读在Dundee 大学的资料科学博士并运用大数据分析在人类蛋白类的实验资料上。他的研究领域包含利用平行化演算法即时分析质谱仪的资料。他也在大学开课教授Hadoop 及MapReduce 程式设计。
三、信号风暴骑士
作者:桑德拉.拉曼 (Sundara Raman)
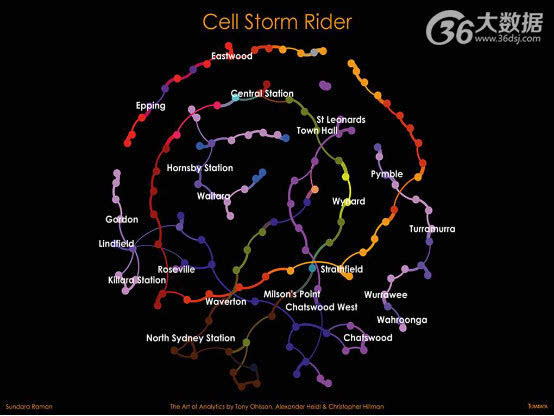
关于洞察
此可视化捕捉了桑德拉.拉曼在澳大利亚悉尼通勤列车廊道的旅程。桑德拉携带其手机和专用软件乘坐列车穿行于悉尼, 由于列车快速穿过城市, 我们可以通过其手机与信号发射塔的连接来跟踪, 用彩点(或节点)描绘在图表上。
利用手机数据对运动中的、聚集大量人群的交通模式进行研究是新分析形式的一部分。其主要目的在于优化发射塔网络、避免性能问题、改善客户体验。但它还能支持新兴数据货币化发展,详细的交通流量信息可用于城市规划、零售商店位置分析和市场营销供应。
桑德拉在分析中探寻能击垮发射塔、影响手机性能的信号“风暴”。当拥挤的通勤列车奔跑于轨道线上,后停于车站,列车发出的100-1000个信号快速移动于各发射塔之间,就足以击垮它们。该可视化是一系列图表的一部分,覆盖了发射塔性能数据、通勤交通流量以及塔切换的信息,准确表现出手机信号的“风暴潮”,从而据此提出详细的建议来优化网络。
图表中还能突显出特定客户体验时由于在4G发射塔(暗点)和低速3G发射塔(亮点)间切换而出现的问题—-信号在发射塔之间来回反复切换,塔信号强度剧烈变化,产生“乒乓效应”。典型代表是位于林菲尔德、可莱雅、怀塔拉、北悉尼以及查茨伍德各车站附近的相连的封闭式发射塔群。
分析方法
该可视化是通过Teradata Aster和Aster Lens实现的。智能手机的遥信数据是从同时使用的3G和4G手机中收集的, 收集在拥挤的公共交通路线上使用专用软件的数据, 地点是沿着澳大利亚悉尼北岸线和史卓菲市交通线一带。分析还包括了对火车站和信号发射塔位置数据的地理空间分析, 从而将位于火车站方圆1公里内的发射塔隔离出来。这个方法有助于衡量确定小范围内,车站周围各发射塔之间信号传播的影响。另外GEXF西格玛图表中还添加了颜色代码, 利用可视化语言统一地区分4G和3G信号发射塔的区域。每种颜色代表一组发射塔的网络覆盖区域。悉尼城市铁路公布的统计数据涉及峰值时间每个车站火车的交通负荷, 分析则利用这一数据关联了手机站点的性能。
作者介绍

桑德拉.拉曼 (Sundara Raman)
桑德拉白天是一位高级电信行业咨询师, 夜间则是一位胸怀大志的数据科学家。他在新西兰梅西大学获得商业管理硕士学位, 现在与妻子及2个孩子住在澳大利亚的悉尼。
桑德拉还是一名发明家, 他曾与他的妻子共同应用“认知行为疗法”(CBT)原则, 设计出“计算机辅助心理评估与治疗”, 获得了澳大利亚一项专利权。
所以, 如果你在下一个日常通勤时碰巧瞥见桑德拉在把玩多个手机, 你就会明白他不是疯了。他只是在利用分析获得深入见解, 从而帮助电信客户改善移动网络的客户体验。
四、互联网络
作者:Yasmeen Ahmad
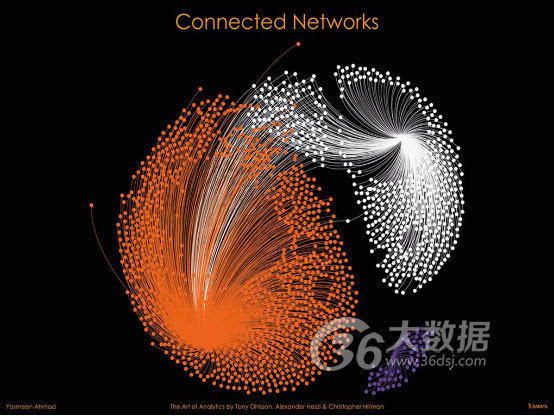
关于洞察
这一匿名可视化报告用于支持一家Telco运营商分析住宅Telco线路。该项目旨在确定线路与网络硬件性能之间的关联,此类关联可能影响到客户体验。
点(节点)代表Telco网络上的DSLAM(数字用户线接入复用器)。DSLAM提供了一项重要服务,能够影响客户呼叫体验;它们可将客户线路连接到主网络。
DSLAM服务级别有多项测量指标,例如衰减、比特率、噪声容限和输出功率,并可针对每条线路整合至三个性能类别。紫色节点显示具备卓越性能的DSLAM,橙色显示具备出色性能的DSLAM,白色显示性能较差的DSLAM。
在图表中,仅少数DSLAM体验到了高质量服务(紫色)。这些 DSLAM 在同一建筑中与主网络基础设施共置,由于靠近中央网络中枢,从而带来了优质服务。大多数客户实现了出色体验(橙色),同时我们发现城市郊区存在服务较差(白色)的DSLAM。
当客户获得可变网络质量时,客户体验和满意度会受到很大影响。Telco的主要目标是确保客户获得一致的体验,即使是那些身处主城市外部的用户也不例外。此图表确定了每个提供可变服务级别的 DSALM;以出色(橙色)和较差(白色)簇之间共享的节点表示。借助这一数据,Telco现在能够调查和优化可变DSLAM。
分析方法
这一西格玛可视化报告使用内建分析和在Teradata Aster平台内发现的可视化创建而成。
收到的数据来自整个城市的住宅线路,其属性包括衰减、比特率等。我们对这些属性进行了整合,以确定表明客户网络体验的性能等级。
这些簇构成了相关性和回归分析的基础,以确定在不同因素下网络性能的变化,这些因素包括:线路技术和长度、调制解调器类型和配置、DSLAM、卡技术、地理位置等。
该西格马可视化图表仅显示了整体分析的一部分,即DSLAM与网络性能间的联系。
作者介绍

Yasmeen Ahmad
Yasmeen是Teradata的最有创意和有见地的数据科学家之一。 Yasmeen在苏格兰长大,她喜欢户外活动,尤其是在苏格兰Munros山和在海上划皮艇。
她在许多国家工作过,包括英国、爱尔兰、荷兰土耳其、比利时和丹麦,她涵盖了金融,电信,零售和公用事业等行业。 Yasmeen专精与企业合作以确定他们的挑战,并将其转化为分析背景。她专注于企业如何利用新的或尚未开发的数据来源,沿着新技术以提高自身的竞争能力的独特能力。
Yasmeen已经与许多分析团队工作,提供领导,培训,指导和实践的支持,提供可操作的见解和经营成果。她使用各种分析方法,包括文本分析,预测建模,归属策略和时间序列分析的发展。她坚信可视化的力量使的在企业用户可以容易进行复杂的沟通。
在Teradata之前,Yasmeen在生命科学行业工作作为数据科学家,建设复杂、多维数据分析管线。 Yasmeen还持有数据管理,挖掘和可视化,这是进行在威康信托中心的基因调控和表达的博士学位。她在国际上发表了多篇论文并在国际会议和活动中演讲。此外,她还在MSc教有关科学数据和商业智能硕士课程。
Yasmeen对于数据分析和可视化有敏锐的热情,通过她的研究中一直好奇地问问题并了解更多信息。这些技能已经允许Yasmeen探索多学科的机会,为她提供了新的无尽的挑战!
五、连续性集装箱修理
作者:Frances Luk

关于洞察
物流集装箱在运输过程中常常会受到损伤,而这些集装箱的修理则依靠世界各地数以百计的供应商来处理。在通常情况下,如果状况不好无法继续使用,受损的集装箱会在被运往下个目的地之前就近修理。我们的客户是全世界最大的一家物流公司,他们希望了解集装箱的修理质量以及各个提供修理的供应商。在进行这项分析之前,客户无法获知集装箱使用寿命当中所发生事件的整体概览。而通过重现每个集装箱使用寿命当中发生的所有事件,我们成功地分析出了集装箱的修理模式。
通过这项分析,客户希望找出因为同一种损伤原因而发生的连续的修理活动,规定这两次修理发生在某一段时间内,或者说第二次修理比预期的时间提前了。这种活动表示早期修理的质量较差,从而造成了第二次的修理。这张桑基图中第一列的方框代表负责第一次修理的国家。
第二列的方框则代表负责第二次修理的国家。从第一列方框直接连到‘结束’框的则代表在第一次修理之后没有再发生修理行为,这是理想的状况;连到第二栏方框的则是意外情况。这张可视化图表让我们的客户得以按地域查看提供修理的供应商,未来还可能在工厂层级继续深钻。
分析技术
集装箱修理活动通过内建的数据装载器从Teradata数据库牵引到了Aster数据库中。我们利用事件序列和模式匹配技术来鉴别连续性修理活动。我们利用这张桑基图来比较不同国家修理工厂的质量,图中的线越粗则表示两个国家共同出现的次数越多。这张图表提供了极佳的整合信息,显示出应该关注于哪个国家,接下去可以利用数据来计算重点关注国家发生第二次修理的相对频率。这张桑基图通过Aster平台中的Aster Lens生成。
作者介绍
Frances Luk
Frances Luk是丹麦哥本哈根团队的一名数据科学家。她从小在香港长大,但某天却决定要去做一些不一样的事情,现在和她的丈夫还有两只可爱的小猫一起在丹麦生活,还拥有哥本哈根大学的硕士学位。在成为数据科学家之前,她曾经用五年时间来开发企业Java应用,并有七年从事银行和物流行业的数据仓库和数据分析的经验,现在负责丹麦和其他北欧国家的跨行业售前和大数据管理PS服务。
Frances对数据科学的热情来源于她强大的技术背景以及她对商业强烈的好奇心。每一比特的数据对她来说都像是一个谜,她喜欢拼凑细节并享受美丽图像产生的那一刻,喜欢看到客户发现未知的洞察时脸上惊叹的表情,这就是她每天工作的功力。
六、集装箱修理波浪
作者:Frances Luk
关于洞察
在通过遍布世界的船舶、卡车、火车进行运输的时候,集装箱时时会受到损伤。损伤情况发生时,集装箱会被运到最近的修理铺里,而这些成百上千个的修理铺散布在世界的各个角落。
我们的客户马士基航运公司希望加强他们对不同修理铺修理质量的了解。过去他们无法在每一个集装箱的层级上对这些数据进行分析,但Teradata Aster平台让马士基航运能够在这个层级调查并分析修理结果,获取有趣的发现、了解它们的模式和趋势,而这是前所未有的。
这张可视化图表中右下方的点代表不同的修理活动,曲线上方的点则表示不同的商品,商品和修理活动之间的连线则代表运输某种商品之后马上发生某种修理活动的频率;连线越粗表示运过某种商品后集装箱发生修理的频率越高。从图中可以看到,最粗的线连接着废金属和底板损伤,也就是说最经常出现的商品和修理类型配对是废金属和集装箱底板修理。
对于马士基航运来说,知道废金属最经常导致破损当然不是什么新鲜事,但采集到的这些数据为将来的分析奠定了强大的基础,(自然可以延伸到考虑比如比起其他货品,是不是更经常要运送废金属)。我们不能完全肯定废金属和底板破损之间的因果关系,但这张可视化图表却突出了问题的规模,建立了马士基航运公司的高级分析团队未来进行更细致的分析时的好的起点。将来的分析工作完成时,最终得到的结果可能就是更差异化的货运定价模型,抵减预计的运后修理成本。
分析技术
集装箱运输和修理活动通过内建的数据加载器从Teradata牵引到Aster当中。通过和马士基航运的ADL(敏捷数据实验室)和AA(高级分析)团队紧密合作,我们确定了适合的途径,用来分析货物和修理之间的关系,并应用模式匹配技术调查连续性运输和修理的模式。
之后我们用sigma可视化工具来展现货物和修理类型之间的关系,这两者在图中表示为实心点,连线的粗细表示共现的次数。初始sigma图通过Aster平台中的Aster Lens生成,现在展现的是优化版本。
作者介绍
Frances Luk,同连续性集装箱修理是一个作者。
七、Terror Report
作者:Kailash Purang

关于洞察
这份资料视觉化是Kailash Purang两部分CIA 报告的第一部分。它展示了进阶分析可以快速地客观地从复杂的文件精炼成简单易懂的视觉化图表。这份图表应该与第两部分的报告(Crown Of Thorns) 一起被检视。
Kailash 刻意挑选了一个具高度政治及情绪相关的主题,这份报告是美国参议院特别委员会研究院针对2001 到2006 年CIA(Central Intelligence Agency) 拘留和审讯程序及审讯拷打的研究。
这是一份相当长的报告,总共从6000 页中有525 页被公开,其中包含特定的政府用词以及在技术文件上会有的专有名词。这是份极端重要的文件以至于少数人可以第一手阅读到并且提供自己的意见,大部分人只能从其他人写的摘要报告接触到。然而像这样泛政治化及情绪性的主题,我们如何确定我们读到的摘要是完全正确且没有其他人的主观意见呢?
简短地来说,这是一个对于测试分析工作是否可以提供一个简单客观的方法来检视报告内容的理想主题。
Kaliash 的第一个视觉化图表”恐怖攻击” 是简单的文字云(word cloud),报告里愈常出现的特定文字在图表上呈现愈大的图形。文字云这样的图表可以很快速被制作,也可以轻易客观被吸收。然而,太粗浅的呈现是它的限制,我们从中可看到关键字,但是并无法从图表中得知任何的细节也无法知道各个主题中间的关联。文字云提供我们一个快速且非常简单的方式来了解报告里的内容。
请接着阅读第二部分“Crown Of Thorrns” 。
分析方法
这份视觉化使用525 页的中央情报局委员拘留及审讯计划报告,这份报告是于2014 年12月9号由美国参议院情报委员会公开发表。
这份图表是使用Wordle 制作的,Wordle 是一个由Jonathon Feinberg发表的文字云制作程式且可以从网站上免费取得。我们可以利用英文里的剔除字(stop word) 来移除低资讯价值的字像”的”跟”了”。制作的图表留下最常出现的字词,读者可以简单地从字词出现的频率得到结论。
作者介绍

Kailash Purang
Kailash 是在Teradata新加坡资料科学家领导人。他也在整个东南亚工作,大部分在印尼支援及领导Teradata在银行及通讯产业客户的服务。
Kailash 有新加坡国立大学经济硕士经济跟统计学学士、新加坡国立大学经济硕士、伦敦大学管理学学士。他在分析领域有长达15年跟产业的经验。
尽管是”出卖灵魂” 投身商业领域,他仍然认为所有这一切的学习和技术的目的是为了让人们的生活更轻松更有趣。为了引进一个有趣的无痛的分析方式,他在业余时间作资料视觉化让每个人都可以从简单的分析应用过程中获益。
作为Teradata资料科学家,他努力使自己的客户实现大数据的全部潜力,使他们的客户可以通过更好的服务和产品受益。
——————
未完待续,明天我们将连载全球最牛的28个大数据可视化应用案例(二)
End.

<!– 访问网络 –>
<uses-permission android:name=”android.permission.INTERNET”/>
<!– 写外部存储 –>
<uses-permission android:name=”android.permission.WRITE_EXTERNAL_STORAGE”/>
<!– 进行网络定位 –>
<uses-permission android:name=”android.permission.ACCESS_COARSE_LOCATION”/>
<!– 访问GPS定位–>
<uses-permission android:name=”android.permission.ACCESS_FINE_LOCATION”/> <uses-permission android:name=”android.permission.ACCESS_MOCK_LOCATION”/>
<!– 获取运营商信息,用于支持提供运营商信息相关的接口–>
<uses-permission android:name=”android.permission.ACCESS_NETWORK_STATE”/>
<!– 访问wifi网络信息,wifi信息可用于进行网络定位–>
<uses-permission android:name=”android.permission.ACCESS_WIFI_STATE”/>
<!– 获取wifi的获取权限,wifi信息可用来进行网络定位–>
<uses-permission android:name=”android.permission.CHANGE_WIFI_STATE”/>
<!– 唤醒CPU –>
<uses-permission android:name=”android.permission.WAKE_LOCK”/>
<!– 控制振动器–>
<uses-permission android:name=”android.permission.VIBRATE”/>
<!– 使用摄像头–>
<uses-permission android:name=”android.permission.CAMERA”/>
<!– 直接拨打电话–>
<uses-permission android:name=”android.permission.CALL_PHONE”/>
<!– 直接发送短信–>
<uses-permission android:name=”android.permission.SEND_SMS”/>
<!– 读取手机当前的状态–>
<uses-permission android:name=”android.permission.READ_PHONE_STATE”/>
<!– 读取手机通讯录–>
<uses-permission android:name=”android.permission.READ_CONTACTS”/>
<!– 写入手机通讯录–>
<uses-permission android:name=”android.permission.WRITE_CONTACTS”/>
<!– 录音–>
<uses-permission android:name=”android.permission.RECORD_AUDIO”/>
<!– 闪光灯–>
<uses-permission android:name=”android.permission.FLASHLIGHT”/>
<!– 读取低级别的系统日志文件–>
<uses-permission android:name=”android.permission.READ_LOGS”/>
<!– 开机启动–>
<uses-permission android:name=”android.permission.RECEIVE_BOOT_COMPLETED”/>
<!– 蓝牙账户–>
<uses-permission android:name=”android.permission.BLUETOOTH_ADMIN”/>
<!– 蓝牙–>
<uses-permission android:name=”android.permission.BLUETOOTH”/>
<!– 手机必要要有照相机 且能自动对焦–>
<uses-feature android:name=”android.hardware.camera”/> <uses-feature android:name=”android.hardware.camera.autofocus” android:required=”false”/> <uses-permission android:name=”android.permission.DOWNLOAD_WITHOUT_NOTIFICATION”/>
Copyright © 2026 优大网 浙ICP备13002865号






{kind=link}